
Structured data in job matching is defined as the practice of organizing job and candidate information into standardized, machine-readable fields that enable algorithms to compare, filter, and rank with accuracy. Fields like job title, location, skills, seniority, salary range, and employment type form the foundation of this system. Without these fields, matching engines rely on free text, which introduces ambiguity and inconsistency. Standards like Schema.org's JobPosting, JSON-LD markup, and AI techniques including TF-IDF and Sentence-BERT all depend on structured inputs to function well. The role of structured data in job matching is not optional. It is the infrastructure that makes precise, fair, and scalable hiring possible.
How does structured data enhance the technical process of job matching?
Structured metadata fields are the engine behind modern job recommendation systems. When a system knows a role's title, location, seniority level, and required skills as discrete, labeled values, it can retrieve and rank candidates far more reliably than when parsing a block of free text. Research shows that metadata-only hybrid systems combining lexical and semantic retrieval achieve a Precision@10 score of 0.8032 and an nDCG@10 of 0.9496 on LinkedIn job data. Those numbers mean that 8 out of 10 top results are genuinely relevant, even without full job descriptions.
The technical process works in layers. Lexical methods like TF-IDF match exact keyword signals. Semantic methods like Sentence-BERT capture meaning beyond exact wording. Structured fields anchor both approaches, giving the model clear signals to work with before it ever touches the prose of a job description.
Here is how the process typically runs:
- Field extraction. Structured fields are parsed from the job posting or candidate profile, including title, location, seniority, and skills.
- Normalization. Values are mapped to standard taxonomies like O*NET or ISCO-08 to reduce inconsistency across employers.
- Hybrid retrieval. Lexical and semantic scores are combined, weighted by field importance.
- Ranking. Results are ordered by a composite relevance score, with structured signals acting as hard filters before soft ranking begins.
Data quality is the critical variable in this chain. Metadata cleaning and validation is crucial because mismatches between structured labels and user-facing content degrade ranking quality directly. A job labeled "Senior" in the metadata but described as "mid-level" in the description creates a contradiction the algorithm cannot resolve cleanly.
Pro Tip: If you are an HR professional building or auditing a job posting workflow, run a spot check on 20 live postings. Verify that the structured metadata fields match the actual job description content. Discrepancies are more common than most teams expect.
What are the practical applications of structured data in recruitment?
Structured data in recruitment does real work at every stage of the hiring process. For job seekers, it determines which roles surface in a search. For HR teams, it controls which candidates reach a recruiter's screen.

The most direct application is skills-based filtering. Structured preference fields like location, salary floor, seniority, and work arrangement filter out poor-fit jobs before a candidate ever sees them. This reduces wasted applications and improves the signal quality for employers. A job seeker who specifies "remote, $90,000 minimum, senior level" gets a fundamentally different results set than one who types the same preferences into a free-text search box.
Governance is the less visible but equally important application. Standardized structured signals enable adverse impact monitoring and defensible, repeatable recruitment decisions at enterprise scale. When every hiring decision is tied to structured data fields, HR teams can audit outcomes by demographic group, identify bias patterns, and produce documentation that satisfies legal and regulatory requirements.
Real-world schema implementation ties these benefits together. Key practical touchpoints include:
- Schema.org JobPosting. This standard defines machine-readable job attributes including title, location, start date, and occupational category using taxonomy codes like O*NET and ISCO-08.
- Google for Jobs. Eligibility requires valid JobPosting structured data with required fields including title, description, datePosted, hiringOrganization, and jobLocation. Adding salary and directApply flags increases visibility.
- ATS integrations. Applicant tracking systems like Workday and Greenhouse rely on structured fields to route, score, and compare candidates consistently across hiring managers.
Pro Tip: Job seekers benefit from structured data too, even if they never see it. When you fill out a profile on a job platform with specific skills, preferred salary, and work arrangement, you are creating structured signals that matching algorithms use to surface your profile. Be specific. Vague profiles produce vague matches.
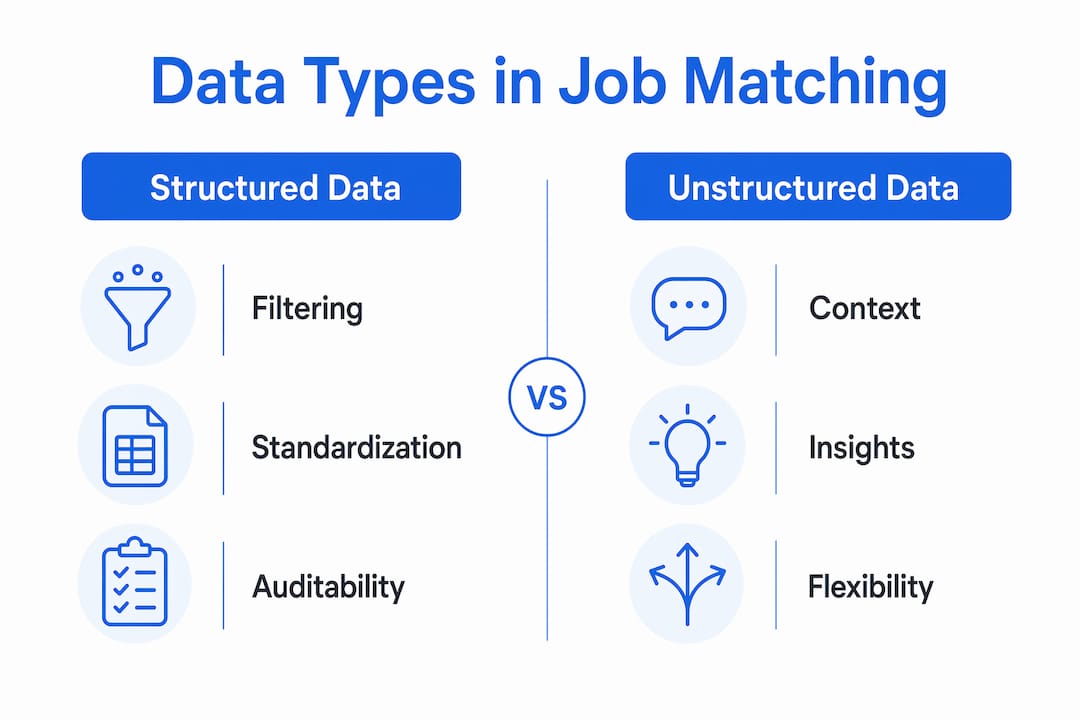
Structured data vs. unstructured data: which works better for matching?
The honest answer is that neither works best alone. Structured and unstructured data serve different functions in a matching system, and the gap between them is a design decision, not a flaw.
| Dimension | Structured data | Unstructured data |
|---|---|---|
| Filtering accuracy | High. Hard filters on salary, location, seniority work reliably. | Low. Free text requires interpretation before filtering. |
| Contextual richness | Limited. Fields capture facts, not nuance. | High. Prose conveys culture, tone, and complexity. |
| Governance and auditability | Strong. Standardized fields support audit trails. | Weak. Narrative text is hard to audit systematically. |
| Semantic flexibility | Low. Mismatched taxonomy terms cause gaps. | High. Natural language handles synonyms and variation. |
| AI compatibility | High. Clean fields reduce model errors. | Moderate. Requires preprocessing and normalization. |
The strongest matching systems use both. Structured fields handle hard constraints. Unstructured text handles soft signals like cultural fit and communication style. Translating messy hiring language into normalized, comparable signals is the hardest part of this process. Seniority labels alone vary wildly across employers. "Senior" at one company is "Lead" at another.
The key challenges with structured data are worth naming directly:
- Schema drift. Field definitions change over time without governance, breaking historical comparisons.
- Semantic mismatch. Ontology-based classification guards against this by mapping extracted entities to standard taxonomies before similarity computation.
- False positives from skill matching. Matching on skills alone is insufficient. Balanced representation of skill coverage, difficulty, and candidate ability is needed to avoid surfacing irrelevant roles.
The practical takeaway for HR professionals: invest in schema governance before scaling AI matching. Clean structured data produces reliable results. Dirty structured data produces confident wrong answers.
What future trends will shape structured data in job matching?
The next wave of improvements in structured data for job matching is already visible in research and early product deployments. Three trends stand out.
AI output reliability through schema constraints. Applying JSON Schema-constrained structured outputs with strict validation improves AI reliability from below 40% to near 100% schema adherence. That shift eliminates the retry loops and parsing errors that make AI job-fit assessments brittle in production. Structured AI architectures with explicit refusals and truncation modes also allow graceful degradation instead of producing misleading fit signals when data is incomplete.
Richer skill taxonomies. O*NET provides standardized occupational data linked to machine-usable skills, abilities, and education requirements for more than 900 occupations. As platforms adopt O*NET and ISCO-08 codes at scale, cross-system matching becomes more consistent. A skill tagged in one ATS can be recognized and compared in another without manual mapping.
Candidate welfare as a matching objective. Current recommendation systems optimized solely for clicks or applications can miss job seeker welfare. Research shows this improves when systems model both application success probability and seeker utility. That shift means future matching systems will weigh whether a role is genuinely good for the candidate, not just whether the candidate is likely to click on it.
Pro Tip: If you are evaluating a job platform or ATS in 2026, ask vendors directly whether their matching system uses schema-constrained AI outputs and whether they model candidate utility alongside employer fit. The answers will tell you a lot about how seriously they take matching quality.
You can also check the job search platform comparison checklist to evaluate how platforms handle structured data implementation before committing to one.
Key Takeaways
Structured data is the foundation of accurate job matching, and its value compounds when paired with strong governance, skill taxonomies, and hybrid AI approaches.
| Point | Details |
|---|---|
| Structured fields drive precision | Hybrid systems using metadata fields achieve Precision@10 scores above 0.80 on real job data. |
| Governance enables fairness | Standardized structured signals support adverse impact monitoring and defensible hiring decisions. |
| Schema standards matter | Schema.org JobPosting and Google for Jobs require valid structured fields to surface roles in search. |
| Hybrid approaches outperform either type alone | Combining structured filters with unstructured text captures both hard constraints and soft context. |
| Data quality determines outcomes | Mismatches between structured labels and job description content directly degrade ranking quality. |
What I've learned from watching structured data get ignored
I've watched a lot of HR teams invest in AI matching tools and then wonder why results feel random. The culprit is almost always the same. The structured data feeding those tools is inconsistent, outdated, or never properly governed in the first place.
Here is what I've found to be true: the quality of your structured data is a ceiling on your matching quality. You cannot build a reliable recommendation engine on top of fields that mean different things in different parts of your ATS. "Senior" in one business unit is not "Senior" in another. "Remote" in one posting means fully remote. In another, it means two days a week from home. Those inconsistencies compound fast.
The fix is less glamorous than buying a new AI tool. It is a governed skills taxonomy, a clear definition for every field, and a process for keeping those definitions current. Maintaining a governed skills taxonomy across ATS, assessments, and reporting systems is more costly than most teams expect. But it is the work that makes everything else reliable.
For job seekers, the lesson is different but related. The platforms that surface the best matches are the ones where you have given the most specific structured signals. Vague preferences produce vague results. Specific skills, a real salary floor, a clear seniority level. Those inputs are what matching algorithms actually use. The more precise you are, the better the system works for you.
The future of job matching is not about more AI. It is about better data feeding that AI. That is a governance problem before it is a technology problem.
— Eric
How Earnhire uses structured data to improve your job search
Earnhire is built on the premise that your job search activity is structured data worth capturing. Every role you save, every resume you tailor, and every preference you set creates signals that inform employers and improve your matches over time.
Unlike traditional job boards that treat search as a passive activity, Earnhire's guided job search tools use structured skills and preference data to surface roles that fit your actual situation, not just your job title. The platform's AI resume tools help you present your experience in the structured format that matching systems recognize and reward. And because Earnhire compensates job seekers for the work of searching, your effort builds real professional value rather than disappearing into a black box. Start building your data worth on Earnhire today.
FAQ
What is structured data in job matching?
Structured data in job matching refers to job and candidate information organized into labeled, machine-readable fields such as job title, skills, location, seniority, and salary. These fields allow algorithms to filter, compare, and rank candidates and roles with accuracy.
How does structured data improve job search results?
Structured preference fields like salary floor, work arrangement, and seniority filter out poor-fit roles before results are shown, reducing wasted applications and improving match quality for both job seekers and employers.
What is Schema.org JobPosting and why does it matter?
Schema.org's JobPosting type defines machine-readable job attributes that enable role discovery across platforms. Google for Jobs requires valid JobPosting structured data with fields like title, description, and jobLocation to surface roles in search results.
What is the difference between structured and unstructured data in recruitment?
Structured data offers strong filtering, standardization, and auditability. Unstructured data like resume prose provides richer context. The strongest matching systems combine both to handle hard constraints and soft signals together.
How does structured data support fair hiring?
Standardized structured signals enable adverse impact monitoring and create audit trails that make recruitment decisions defensible and repeatable. Governance layers built on structured data reduce subjectivity before AI tools are ever applied.